

Natural Image







... slide to see more examples ...
We present the Draw-and-Understand framework, exploring how to integrate visual prompting understanding capabilities into Multimodal Large Language Models (MLLMs). Visual prompts allow users to interact through multi-modal instructions, enhancing the models' interactivity and fine-grained image comprehension. In this framework, we propose a general architecture adaptable to different pre-trained MLLMs, enabling it to recognize various types of visual prompts (such as points, bounding boxes, and free-form shapes) alongside language understanding.
Additionally, we introduce MDVP-Instruct-Data, a multi-domain dataset featuring 🔥1.2 million {image, visual prompt, text} triplets, including natural images, document images, scene text images, mobile/web screenshots, and remote sensing images. Building on this dataset, we introduce MDVP-Bench, a challenging benchmark designed to evaluate a model’s ability to understand visual prompting instructions.
The experimental results demonstrate that our framework can be easily and effectively applied to various MLLMs, such as SPHINX-X and LLaVA. After training with MDVP-Instruct-Data and image-level instruction datasets, our VP-MLLM exhibit impressive multimodal interaction capabilities and pixel-level understanding, while maintaining their image-level visual perception performance.
We will detail the process of integrating visual prompt understanding into pre-trained MLLMs and transforming them into Visual Prompting MLLMs (VP-MLLM), as well as the training strategy designed to enhance alignment and fine-tuning for VP-MLLMs below.
For most existing MLLMs, the overall architecture consists of three components: a vision encoder, a tokenizer (text encoder), and a Large Language Model (LLM). Each modality is processed by its corresponding encoder, and the resulting tokens are concatenated and fed into the LLM for learning. Similarly, to achieve visual prompting understanding, we incorporate a visual prompt encoder to embed the input visual prompts. This integration allows us to combine the image, visual prompt, and language representations and forward them collectively to the LLM:
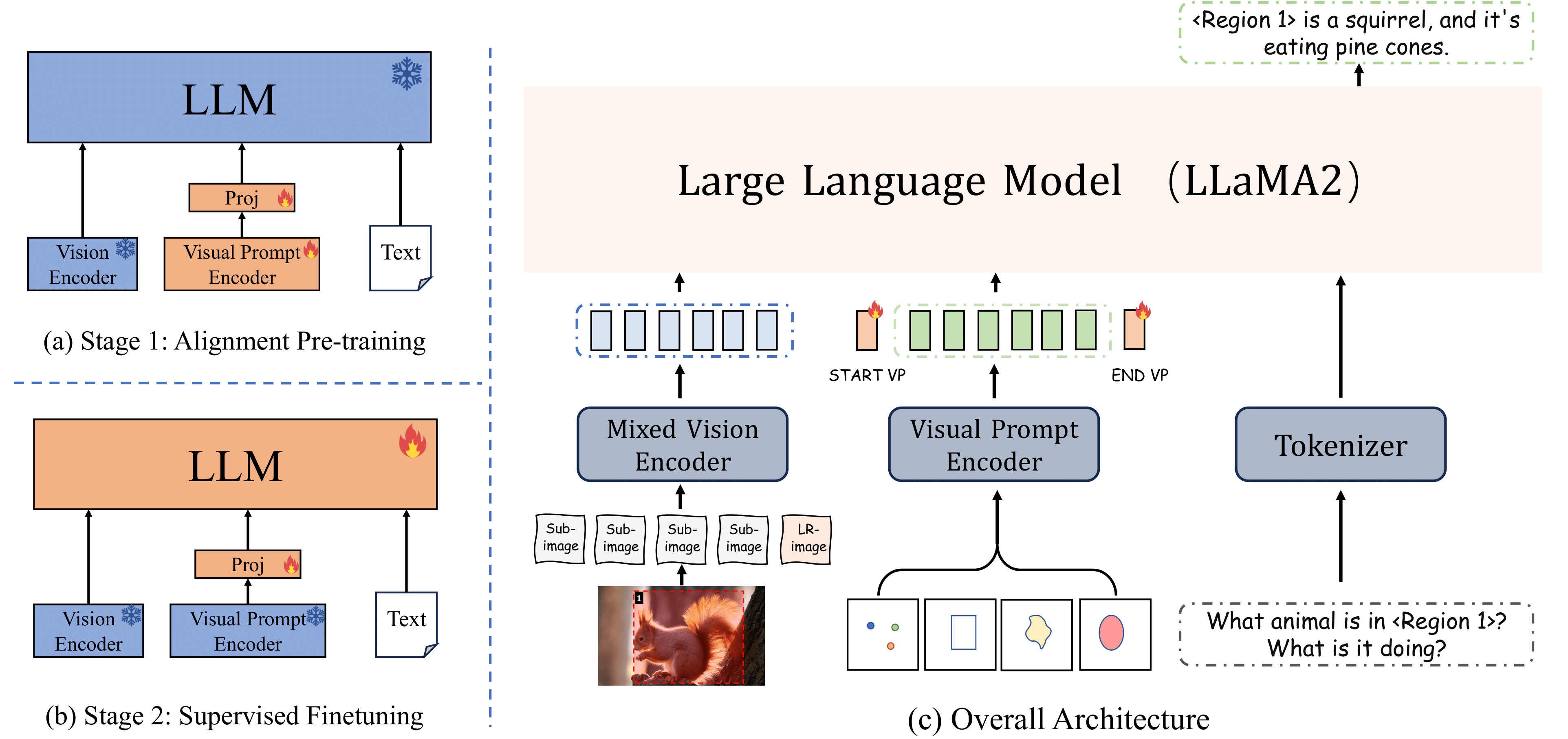
As shown in Figure(b) above, we introduce a simple yet effective visual prompt encoder that focuses on two types of visual prompts: points and bounding boxes. Initially, the encoder utilizes positional encoding for the coordinates of both points (center) and boxes (top-left and bottom-right corners). It then adds three distinct learnable embeddings for each corner and processes them through a linear layer to obtain unified output embeddings. Additionally, we accommodate a dynamic number of visual prompts as input. We first set a fixed number of visual prompt tokens (16). Based on the validity of the actual input tokens, we provide both valid and invalid tokens with a set of learnable vectors to help the model discern their effective features. Finally, we employ a linear layer to map the embeddings of different prompt types to the same dimension, thereby unifying the various visual prompt inputs.
VP-MLLM is trained in two stages:
We initially freeze both the pre-trained vision encoder and the LLM, then focus on training the features of visual prompts to align with those of the input image and text. Following the approach in LLaVA, we implement an MLP to transform the visual prompt tokens into the latent space of the LLM. We use open-source detection and segmentation datasets to create our stage 1 training data. These datasets include a wide range of objects and label types, such as elements of the natural world (e.g., people, animals, objects), remote sensing (e.g., buildings, roads, vehicles, water bodies), document components (e.g., titles, paragraphs, images, tables), OCR data (e.g., text recognition), and screenshots (e.g., icons, text, search bars). For point visual prompts, we randomly sample pixels from semantic segmentation images, where each point corresponds to a pixellevel label annotation. For box visual prompts, we directly use the ground truth bounding boxes from detection datasets as inputs, enabling the model to recognize their corresponding labels. With this rich and diverse data for pre-training, the model is well-equipped for visual prompting and object categorization.
At this stage, we load the weights trained from stage 1 and keep the vision encoder and visual prompt encoder weights frozen. We then fine-tune the visual prompt projector and the LLM. This stage focus on enhancing model’s ability to accurately interpret user instructions and handle diverse visual prompting understanding tasks, such as detailed captioning, inter-relationship analysis, and complex reasoning, while maintain the original robust vision-language global understanding capability.
 MDVP-Data: Multi-domain Visual-Prompt Instruction Dataset
MDVP-Data: Multi-domain Visual-Prompt Instruction Dataset
We introduce MDVP-Data, an instruction dataset designed to foster fine-grained and open-world image understanding in MLLMs, encompassing approximately 1.6 million multimodal dialogues. MDVP-Data integrates both point-level and region-level instruction data derived from public datasets. It consists of two types of data:
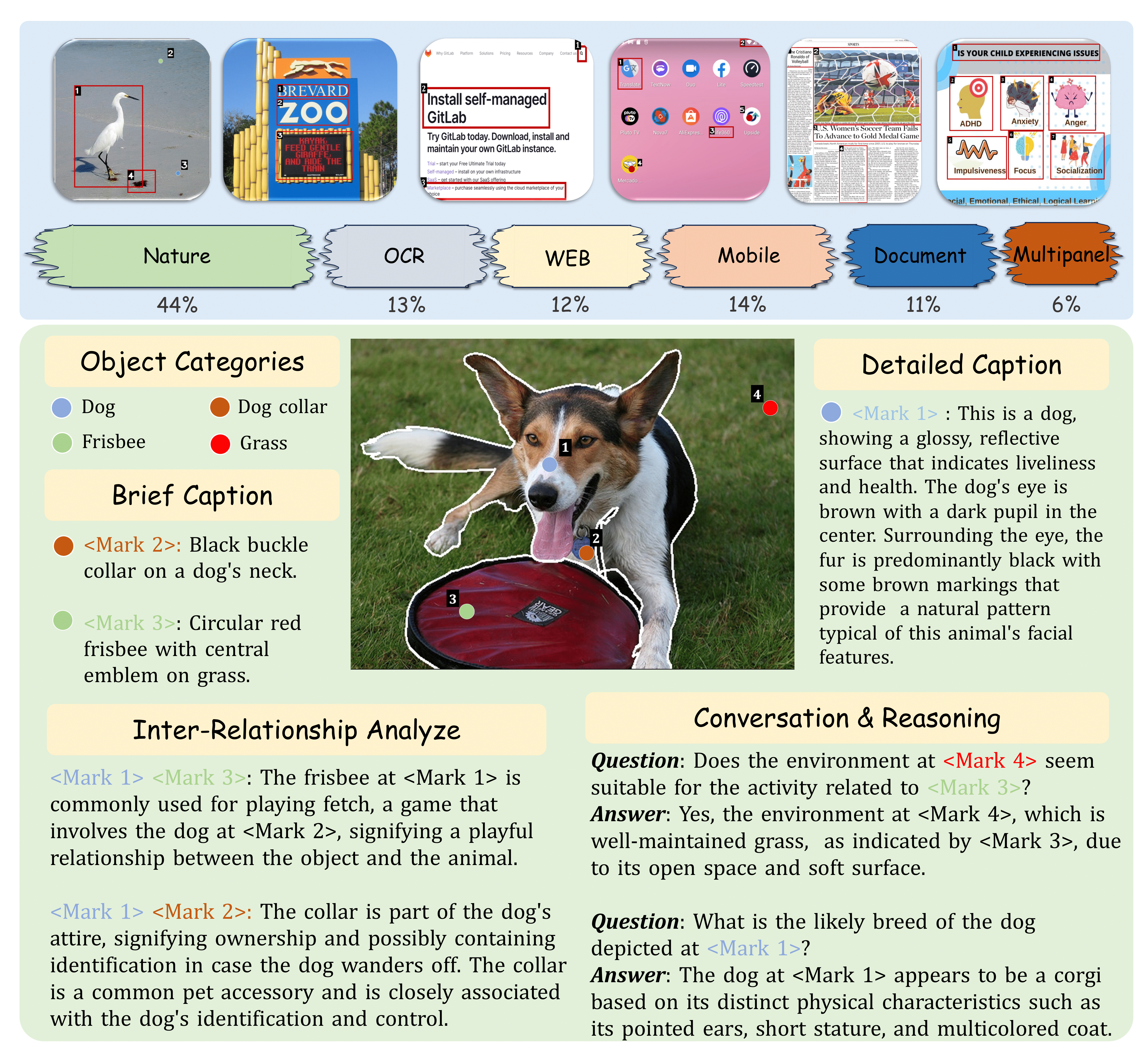
Above diagram displays the distribution of images drawn from various sources, including nature scenes, OCR texts, remote sensing scenes, web content, mobile interfaces, documents, and multi-panel graphics. It also features a sample from the GPT-assisted MDVP dataset, emphasizing the diversity and richness of its point-based and region-based instruction-following data.





 Performance
Performance
 Traditional Evaluating Task
Traditional Evaluating Task
For evaluation, we primarily use two popular MLLMs: SPHINX-X and LLaVA-Next, along with three model sizes: 7B, 8B, and 13B. In both visual prompt-based and traditional tasks, VP-MLLM significantly outperforms existing visual-prompt-based methods.
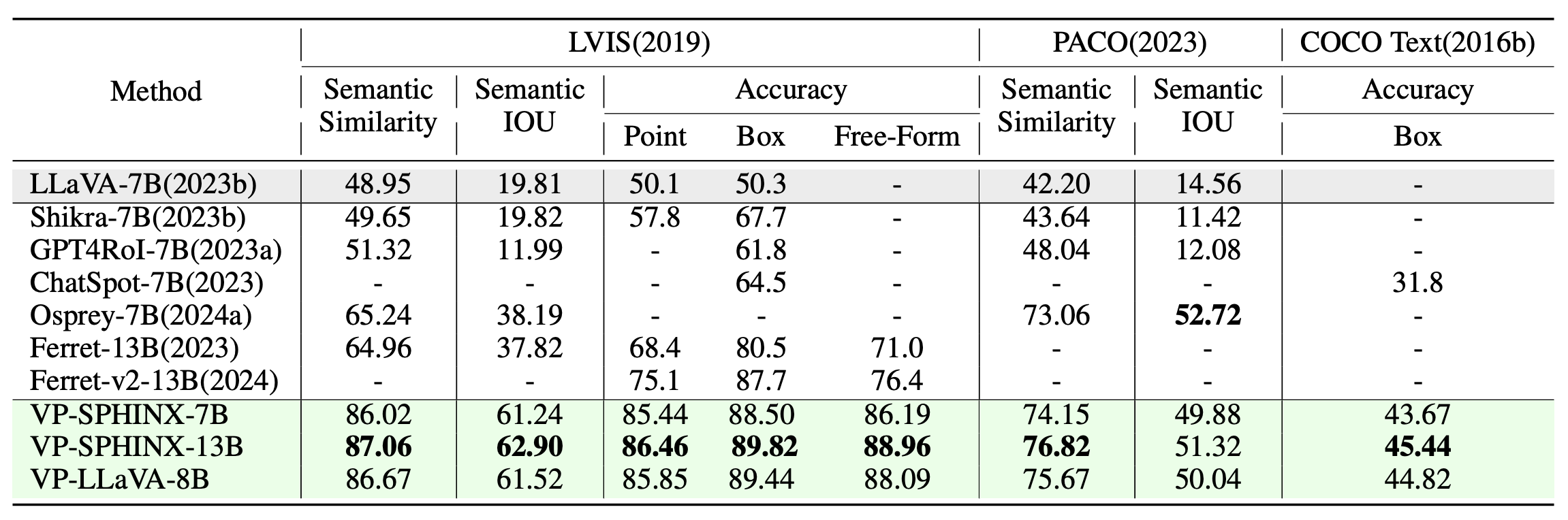
Results of referring classification on LVIS and PACO, and COCO text. Calculation of Semantic Similarity and Semantic IOU was performed using box visual prompts.
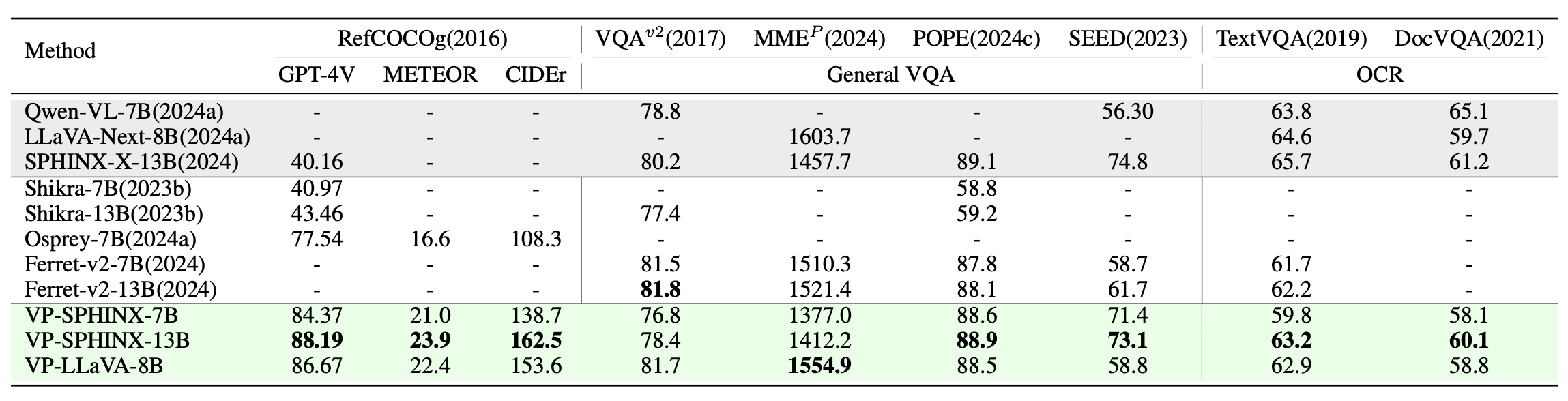
Region-level captioning performance on the validation set of RefCOCOg and performance comparison on general MLLM benchmarks including VQA and OCR.
Region-level captioning performance on the validation set of RefCOCOg and performance comparison on general MLLM benchmarks including VQA and OCR.
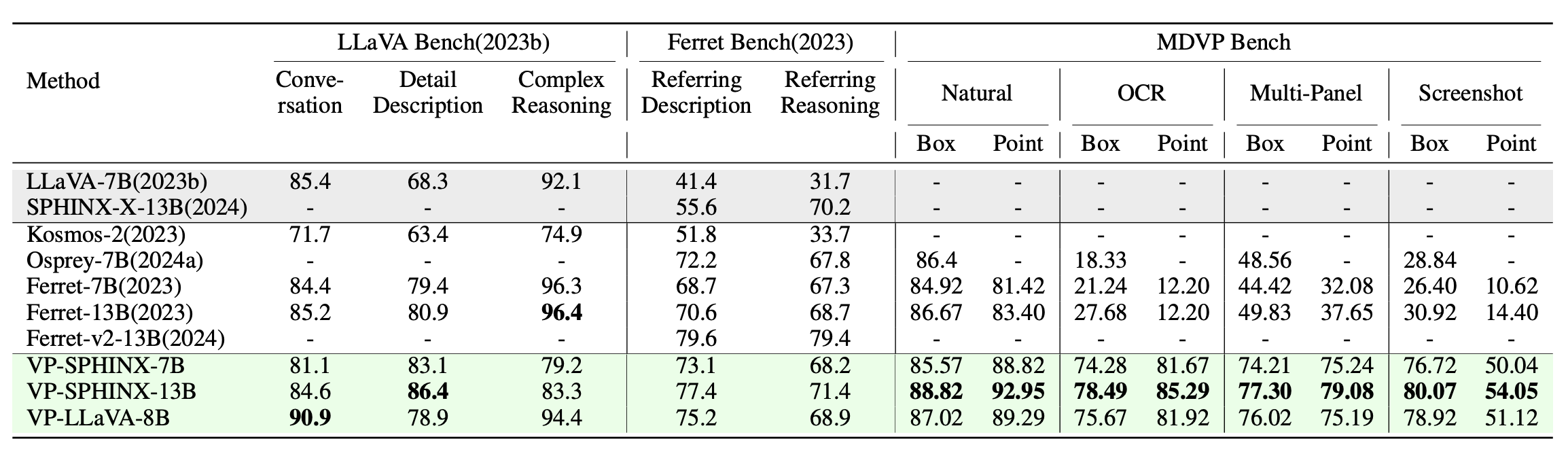
Performance on the LLaVA Bench, Ferret Bench, and our MDVP Bench.
 MDVP-Bench
MDVP-Bench
To evaluate the proficiency of the MLLM in complex pixel-level image understanding tasks and its versatility across various domains, we initially curated a subset of our MDVP-Data. This subset underwent a thorough manual content review and filtering process, resulting in the creation of MDVP-Bench. MDVP-Bench is a comprehensive and challenging benchmark covering a wide range of tasks, including concise descriptions, elaborate narratives, analyses of interconnections among different regions, and complex reasoning. The performance of existing visual-prompt-based methods on MDVP-Bench is as follows:
@article{lin2024draw,
title={Draw-and-understand: Leveraging visual prompts to enable mllms to comprehend what you want},
author={Lin, Weifeng and Wei, Xinyu and An, Ruichuan and Gao, Peng and Zou, Bocheng and Luo, Yulin and Huang, Siyuan and Zhang, Shanghang and Li, Hongsheng},
journal={arXiv preprint arXiv:2403.20271},
year={2024}
}